What’s new in 4.0.0 (2024-11-18)#
New features#
Transition graph#
Added a main threshold on the canvas for easier node filtering.
Added two-sided thresholds for filtering nodes and edges in the left-side bar.
Improved visualization of the incoming and outcoming edges when clicking on a node.
Added import & export of the whole graph, not nodes layout only as it was previously. See the transition graph user guide for more details.
Thresholds on the left-side panel are synchronized with the weight column chosen.
Eliminated eye icon for hiding nodes. Switcher icon is left as the only way to hide nodes from the canvas.
Segments#
Segments is a brand new feature that allows you to divide an eventstream into segments and compare them.
Segments can be either static (e.g. user gender, marketing source, AB-test group) or dynamic (e.g. first user date, before or after release date, or an arbitrary user state). Segments are effectively stored in the eventstream as synthetic events.
Some visualization tools support segment comparison. See
Eventstream.step_matrix(),Eventstream.transition_matrix().Segments can be also compared with new visualization tools:
Eventstream.segment_overview(),Eventstream.segment_diff().The
Eventstream.filter_events()data processor now supports filtering by a segment value.The
Eventstream.projection()visualizing tool has been refactored. Now it supports sampling to speed up the visualization of large datasets. It also supports easier segment comparison by switching the colors related to different segments.
Here is how you can quickly exhibit the difference between two segments US VS UK or US VS its complement _OUTER_ (assuming that you have a column country in your eventstream):
stream = stream.add_segment('country')
stream.step_matrix(groups=['country', 'US', 'UK'])
stream.transition_matrix(groups=['country', 'US', '_OUTER_'])
See the segments user guide for more details.
Clusters#
The Clusters module have been fully reworked. Path-cluster mapping is stored as a segment. All segment comparison tools are valid for cluster analysis as well. Working with clusters is designed now as a set of Eventstream class methods instead of a separate Clusters class.
New clustering algorithm HDBSCAN has been added.
A special tool
Eventstream.clusters_overview()has been tailored for cluster analysis.Eventstream.segment_diff()now allows to compare feature distributions between clusters: numerically (using Wasserstein’s distance) and visually (using density plots).For the K-Means clustering algorithm, the elbow curve visualization has been added to help choose the optimal number of clusters.
The
extract_featuresmethod has been moved to Eventstream methods.
Below is an example of how you can split user behavior into clusters and analyze them with few lines of code
features = stream.extract_features(ngram_range=(1, 1), feature_type='count')
stream = stream.get_clusters(
features,
method='kmeans',
n_clusters=8,
random_state=42,
segment_name='kmeans_clusters'
)
and overview the clusters with the features and additional custom metrics
custom_metrics = [
('segment_size', 'mean', 'cluster size'),
('len', 'mean', 'path_len, mean'),
('has:payment_done', 'mean', 'CR: payment_done'),
(lambda _df: (_df['event'] == 'catalog').sum(), 'median', 'catalog, median'),
(pd.NamedAgg('timestamp', lambda s: len(s.dt.date.unique())), 'mean', 'Active days, mean')
]
stream.clusters_overview('kmeans_clusters', features, aggfunc='mean', metrics=custom_metrics)
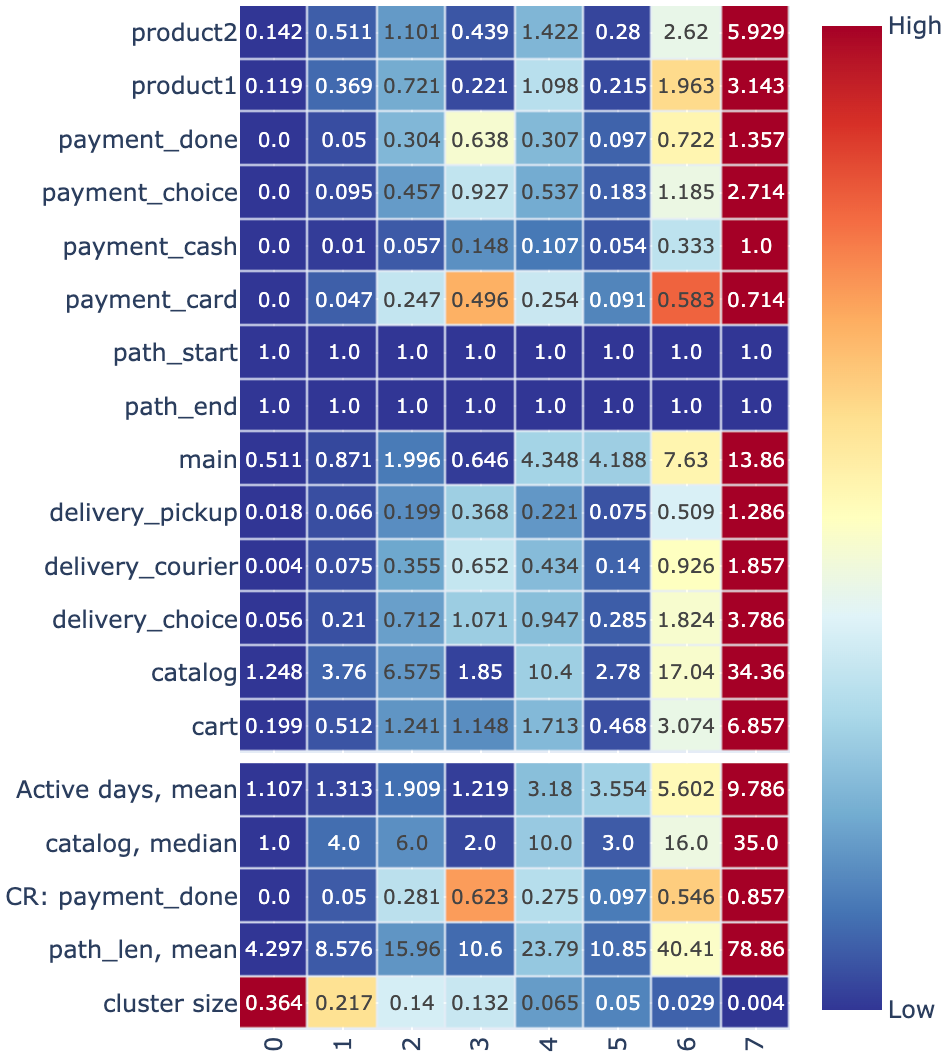
or compare the feature distributions between particular clusters
stream.segment_diff(['kmeans_clusters', '2', '4'], features)
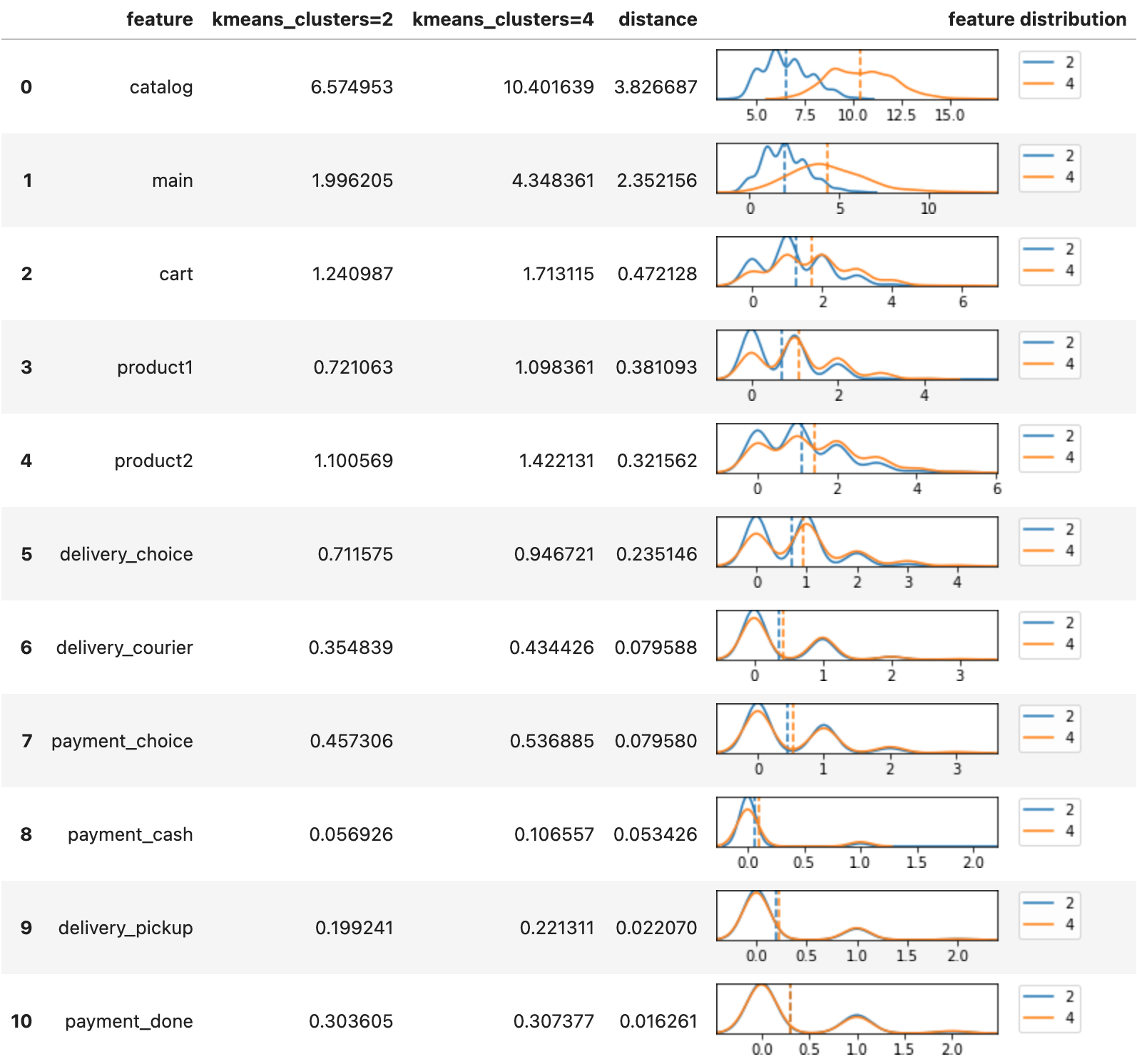
See the clusters user guide for more details.
Transition matrix#
Transition matrix has been redesigned as a separate visualization tool.
Group comparison is now supported.
The default value of the
weight_colargument is changed touser_idso the values represented in a matrix are the numbers of unique users who experienced a given transition.
This how you can look at the difference between two segment values of a binary segment Apr 2020. See the transition matrix user guide for more details.
stream.transition_matrix(groups='Apr 2020', norm_type='node')
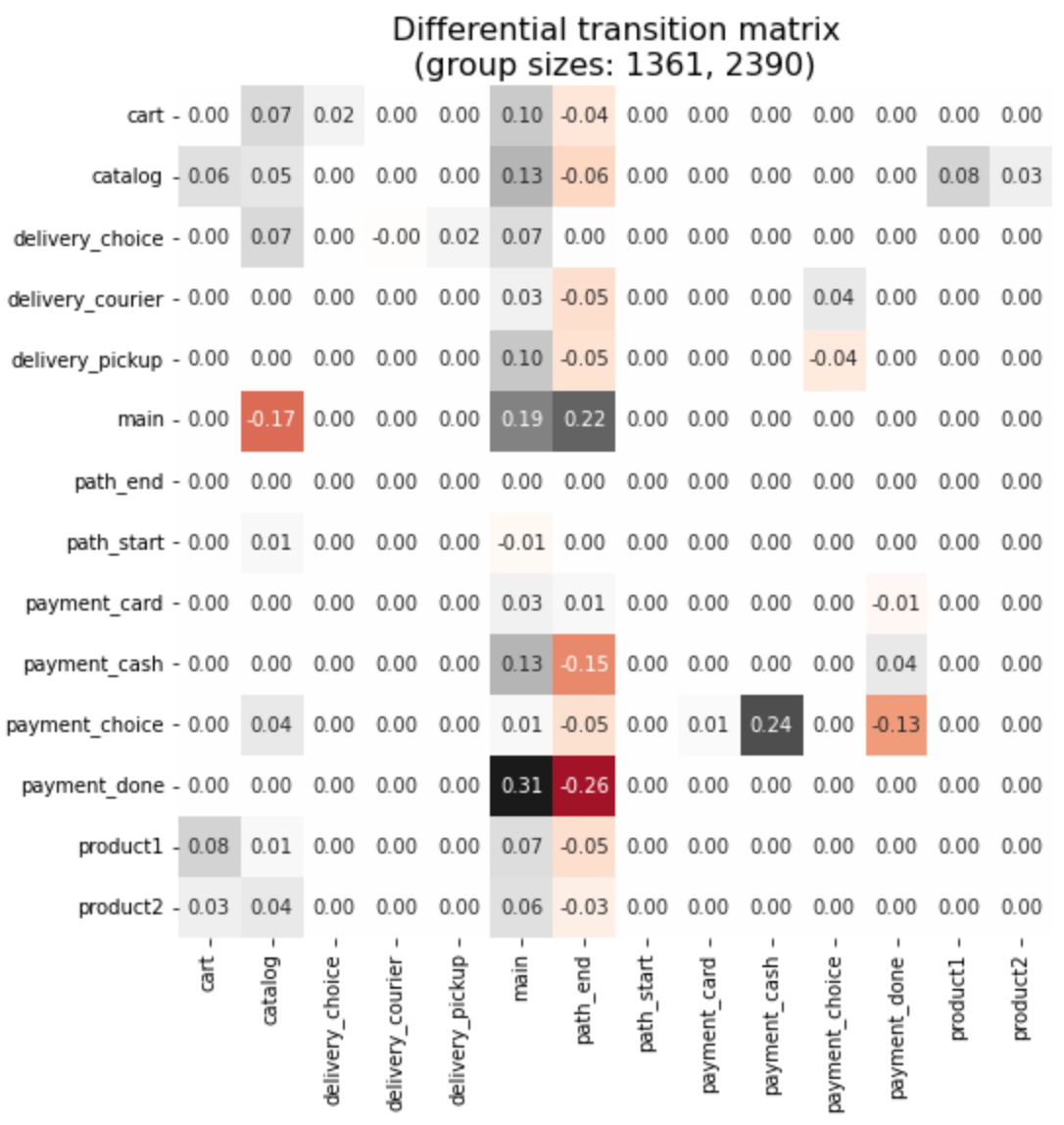
Other features#
Added a new method
Eventstream.path_metrics()for calculating arbitrary metrics for paths. Added special shortcuts such aslen,has:TARGET_EVENT,time_to:TARGET_EVENTfor common metrics. Here is a simple example of how to use it applied to thecartevent:
metrics = [
# path length
('len', 'path_length'),
# True if there's a cart event in a path, otherwise False
('has:cart', 'has_cart'),
# Time from the path start to the first occurrence of the cart event.
('time_to:cart', 'time_to_cart'),
# The number of cart events in a path
(lambda _df: (_df['event'] == 'cart').sum(), 'cart_count'),
# The number of unique days in a path
(pd.NamedAgg('timestamp', lambda s: len(s.dt.date.unique())), 'active_days')
]
stream.path_metrics(metrics).head()
| path_length | has_cart | time_to_cart | cart_count | active_days | |
|---|---|---|---|---|---|
| 122915 | 34 | True | 6 days 01:22:39.090422 | 1 | 2 |
| 463458 | 12 | False | NaT | 0 | 1 |
| 1475907 | 16 | True | 23 days 13:03:45.213509 | 1 | 2 |
| 1576626 | 3 | False | NaT | 0 | 1 |
| 2112338 | 7 | False | NaT | 0 | 1 |
Improvements#
Python 3.12 is supported now. Python 3.8 is not supported anymore.
Many libraries that are used in the project have been updated to the latest versions. In particular, pandas 2.2, numpy 2.0, scikit-learn 1.4 are supported now.
Improved the performance of some tools and data processors:
CollapseLoops, centered step matrix, Eventstream constructor.