Sequences#
![]()

Basic example#
Sequences is a tool that displays the frequency of n-grams. n-gram is a term referring to event sequence of length n. For example, a path A → B → C → D contains two 3-grams: A → B → C and B → C → D.
Hereafter we use simple_shop dataset, which has already been converted to Eventstream and assigned to stream variable. If you want to use your own dataset, upload it following this instruction.
from retentioneering import datasets
stream = datasets.load_simple_shop()
To run sequences tool, use the Eventstream.sequences() method.
stream.sequences()
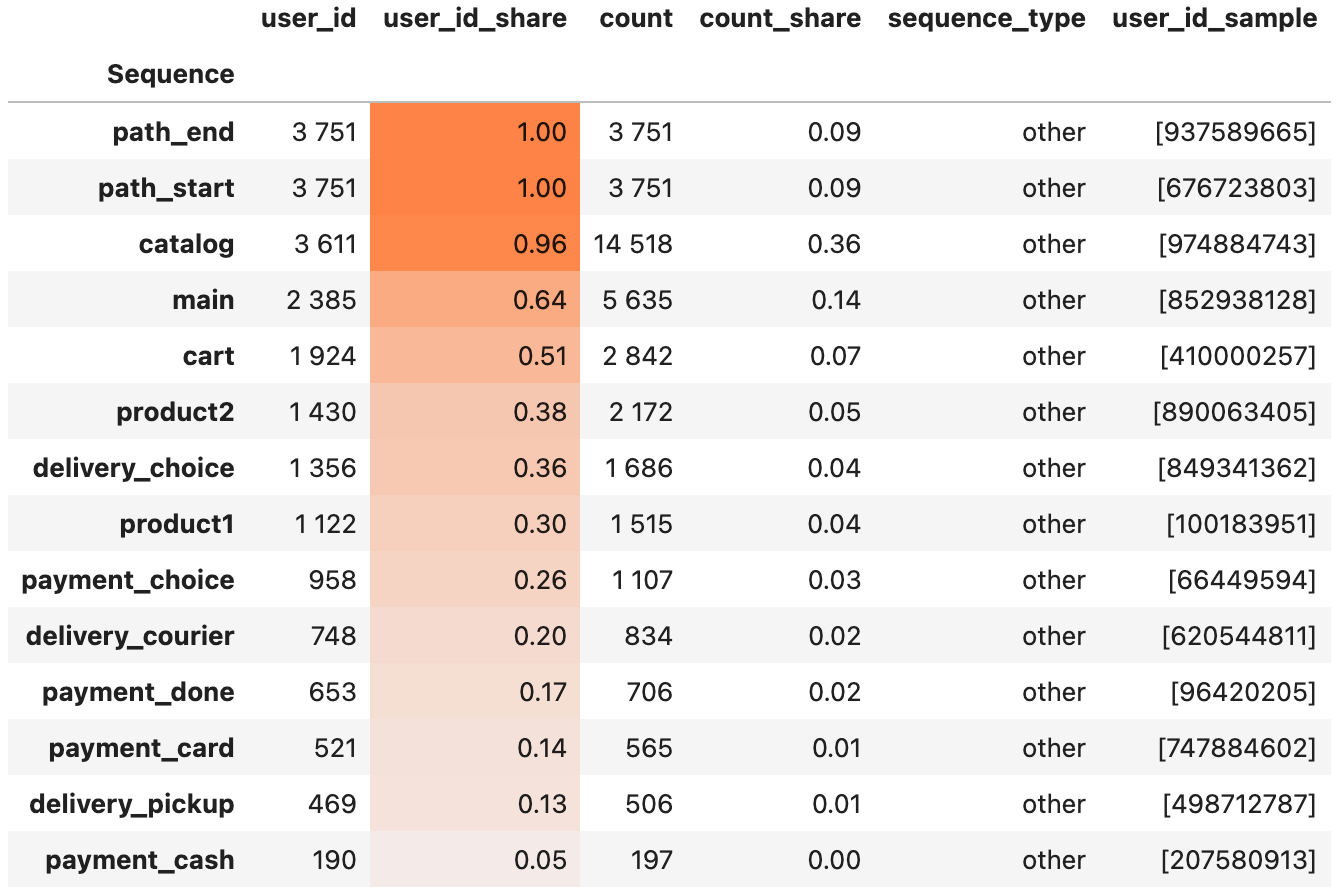
Let us explore the output. The output is a pandas DataFrame colored with a heatmap. Particular sequences form the DataFrame index. By default, single events are considered as sequences (1-grams). To adjust this behavior use ngram_range argument.
The columns mostly display metrics that reflect frequency of a particular n-gram. The possible metrics are:
paths. The number of unique paths that contain a particular event sequence.paths_share: The ratio of paths containing a sequence to the total number of paths.count: The number of occurrences of a particular sequence (might occur multiple times within a path).count_share: The ratio of a particular count to the sum of counts over all sequences.
sequence_type column allows to differentiate important types of sequences: loops and cycles. A sequence of length >= 2 is a loop if it consists of a single unique event. A sequence of length >= 3 is a cycle if its starting and ending event are the same events.
Finally, path_id_sample column contains samples of random path ids that contain given sequence. They are useful when you need to explore deeper why a particular sequence could occur.
Note
paths and paths_share metric names are replaced with the corresponding weight_col values in the output. Namely, for the default weight_col='user_id' value, user_id and user_id_share are used as the column titles. Also, path_id_sample is replaced with user_id_sample.
Tuning the arguments#
Now let us consider another example to demonstrate how the arguments can be tuned. We also use here the SplitSessions data processor in order to split the eventstream into sessions and get additional session_id column.
stream\
.split_sessions(timeout=(30, 'm'))\
.sequences(
ngram_range=(2, 3),
weight_col='session_id',
metrics=['count', 'count_share', 'paths_share'],
threshold=['count', 1200],
sorting=['count_share', False],
heatmap_cols=['session_id_share'],
sample_size=3
)
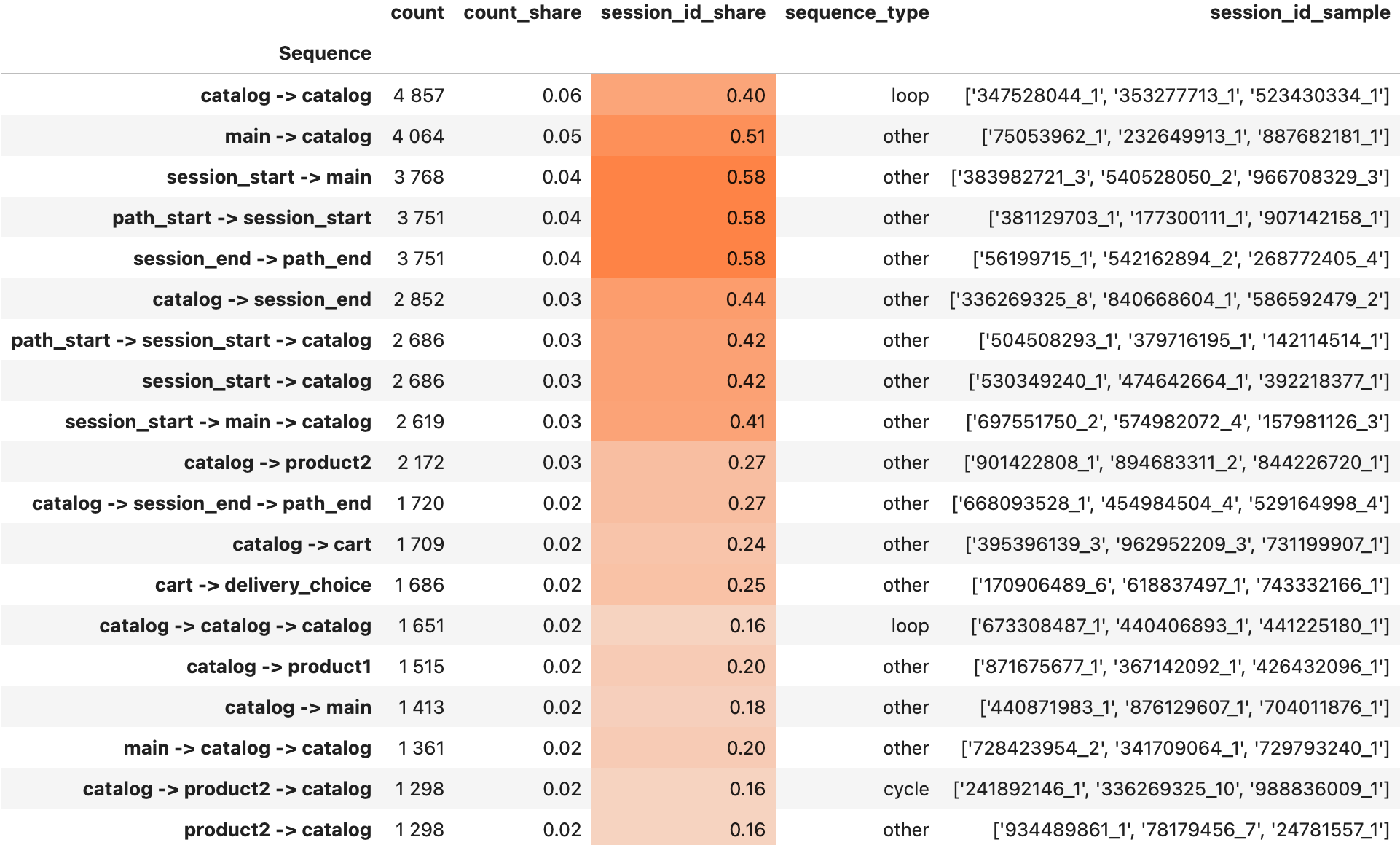
To set the range of n-gram length (i.e. n) use ngram_range argument. This is a very important parameter because it limits the number of all possible n-grams to be discovered. If the upper length is set too high, the number of n-grams might be immense, so it takes much time to compute them all. In practice, it is rarely reasonable to compute all the n-grams of length >= 6-7. So be careful with it.
weight_col sets the eventstream column that contain path identifiers. Similar to transition graph and step matrix, you can calculate the sequence statistics within a whole path (by user_id) or within its subpaths (for example, by session_id). In this example we switch it to weight_col='session_id'.
metrics parameter defines the metrics to be included in the output columns. The metric names were defined in the previous section.
Since the number of all sequences is often large we usually need to include in the output the most valuable sequences. With the threshold parameter you can define a column to be used as a filter and the corresponding threshold value. The values above given threshold are included in the output. In the example we define threshold=['count', 1200] meaning that the filtering column is count and the threshold value is 1200.
Sorting of the output table is controlled by the sorting parameter. The heatmap is defined by heatmap_cols parameter. Note that instead of heatmap_cols=['session_id_share'] we could use heatmap_cols=['paths_share'] which would be an alias in case of weight_col='session_id'.
Finally, the sample_size parameter defines the length of the list with sampled path_ids.
Comparing groups#
One of the most powerful application of the Sequences tool is comparing sequences frequencies between two groups of users. We will use a random split of the users just for demonstration purposes.
np.random.seed(111)
users = set(stream.to_dataframe()['user_id'])
group1 = set(np.random.choice(list(users), size=len(users)//2))
group2 = users - group1
stream.sequences(
groups=[group1, group2],
group_names=['A', 'B'],
metrics=['paths_share', 'count_share'],
threshold=[('user_id_share', 'delta_abs'), 0],
sorting=[('count_share', 'delta'), False]
)
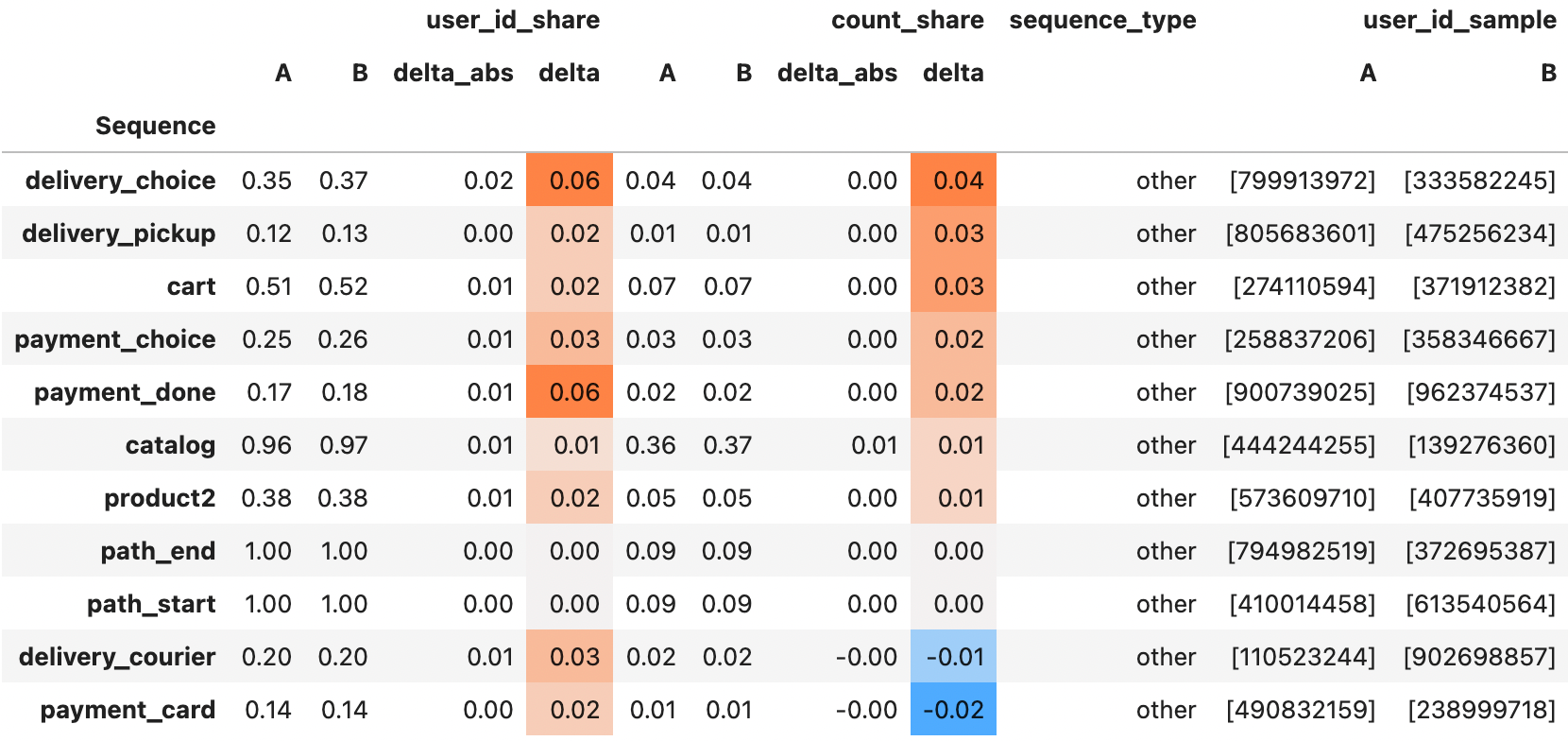
To activate group mode for Sequences, you simply need to set groups parameter that defines two sets of users to be compared. Optionally, you can define the names of these groups with group_names parameter so the output columns will be labeled with the corresponding titles.
Metrics columns are designed as follows. Each metric is represented with four columns:
metric value for the first group (A),
metric value for the second group (B),
delta_abs: the metric difference between the second and the first group (B - A),delta_res: the relative value of the delta compared to the value for the first group (B - A) / A.
Unlike regular output, Sequences output for groups contains pandas.MultiIndex in the columns. So while using threshold, sorting, and heatmap_cols you need to refer a column as an element of 2-level multiindex.
Common tooling properties#
values#
If you want to get the underlying pandas DataFrame you can use property Sequences.values. An additional flag show_plot=False supresses the output.
seq_df = stream.sequences(show_plot=False).values
seq_df
| user_id | user_id_share | count | count_share | sequence_type | user_id_sample | |
|---|---|---|---|---|---|---|
| Sequence | ||||||
| path_end | 3751 | 1.00 | 3751 | 0.09 | other | [696492792] |
| path_start | 3751 | 1.00 | 3751 | 0.09 | other | [807066609] |
| catalog | 3611 | 0.96 | 14518 | 0.36 | other | [969637876] |
| main | 2385 | 0.64 | 5635 | 0.14 | other | [274091445] |
| cart | 1924 | 0.51 | 2842 | 0.07 | other | [712986878] |
| product2 | 1430 | 0.38 | 2172 | 0.05 | other | [196471324] |
| delivery_choice | 1356 | 0.36 | 1686 | 0.04 | other | [162041520] |
| product1 | 1122 | 0.30 | 1515 | 0.04 | other | [368983170] |
| payment_choice | 958 | 0.26 | 1107 | 0.03 | other | [418845606] |
| delivery_courier | 748 | 0.20 | 834 | 0.02 | other | [397948421] |
| payment_done | 653 | 0.17 | 706 | 0.02 | other | [827859068] |
| payment_card | 521 | 0.14 | 565 | 0.01 | other | [204780950] |
| delivery_pickup | 469 | 0.13 | 506 | 0.01 | other | [470581033] |
| payment_cash | 190 | 0.05 | 197 | 0.00 | other | [766327250] |